上一篇我们聊了售前如何跳出PPT工具人的内耗,本质上是聊「不追规模,深耕核心效率」,今天这篇文章,刚好是这个逻辑在AI行业最极致的印证。
过去半年,每当有人问“DeepSeek是不是不行了”,我的回答都一样:别急。
倒不是对这家公司有什么迷信,而是我观察到一个有趣的反差:当整个AI圈都在把模型越做越臃肿的时候,只有DeepSeek在拼命研究一件事——如何用更少的资源,干出更漂亮的结果。这在算力充裕的年代算不上性感叙事,但在全球算力荒席卷行业的今天,突然成了所有人都想抄的标准答案。
去年R1发布时,所有人都被它的推理能力镇住了。但很少有人注意到,那篇论文真正的灵魂是极致成本控制——只花了几百万美元的训练费用,就做到了海外头部厂商几亿美元才落地的同级别推理级大模型效果。当时不少海外同行并不服气,觉得这只是中国公司在硬件受限下逼出来的权宜之计,是不得已走的“极限性价比”野路子。
现在V4出来了,那些不服的声音基本消失了。因为这一版不仅仅便宜,而是在编程、长文本、推理效率三个硬维度上,追平甚至反超了海外最顶尖的闭源模型。更关键的是,它向整个行业证明了一件事:在硬件封锁下磨出来的效率革命,恰好撞上了全球AI最迫切的痛点。
当全世界都在“算力地狱”门口排队
先看一个大背景。
今年CES上,AMD CEO苏姿丰给出了一组让人头皮发麻的数字:2022年全球AI算力需求约1 exaflop,2025年已飙至100多exaflop,2026-2030年预计还要再翻100倍。翻成大白话就是——AI对芯片和电力的吞噬速度,远远超过了人类建设基础设施的速度。
这不是某一家公司的困境,而是全行业的物理瓶颈。马斯克在今年的一次内部会上也挑明了:下一代Grok的训练,算力将是最大的挑战,不是钱能解决的问题。
为什么会突然这么缺算力?因为AI从“会说话”进化到了“会干活”。
以前的对话式AI,你问它答,一轮几百个token就结束了。现在的Agent任务则完全不同:模型要反复调用工具、生成代码、验证结果、发现错误再重来。根据调研机构的数据,token消耗量是原来的5到50倍。AI终于长出了能落地干活的手和脚,代价却是对算力的指数级吞噬。大模型厂商、科研机构、云数据中心,全都陷在算力短缺的泥潭里难以脱身。
DeepSeek的“吝啬”哲学,突然变成了最前沿的战略
这时候再回看DeepSeek的做派,你会发现一个黑色幽默:一个被芯片禁令逼出来的“省钱团队”,恰好撞上了全人类最需要的解题方向。
翻完V4的技术文档,我最大的感受是——它的每一项升级,几乎都不是为了“更庞大”,而是为了“更节省”。
MoE(混合专家)稀疏激活架构是最好的例子。V3有256个专家,每次激活8个;V4把专家池扩到了384个,听起来更庞杂了,但它每次只激活6个——处理同样任务时,实际调用的计算资源不增反降。
用大白话解释:这就像一家餐厅,后厨的顶级大厨从8个扩充到384个,但每道菜只需要6个人协作,其他厨师全部待命。上菜速度一点没慢,但团队的专业细分能力提升了不止一个量级。我不知道这是不是理论上的技术最优解,但它完美解决了一个行业最真实的痛点:在芯片供给受限、算力持续吃紧的前提下,如何维持甚至大幅提升模型的推理能力与聪明度。
这套逻辑还有一个配套动作:全新的混合注意力架构——上下文稀疏注意力CSA与混合因果注意力HCA,让长文本处理的计算量实现断崖式下降;革命性的训练方案Muon优化器,只用传统方法大概一半的计算量就能达到同等效果。根据技术报告的数据,在100万token上下文、同等推理效果的场景下,V4 Pro的单token推理计算量仅为V3.2的27%,KV缓存仅为10%。每一行代码都在回答同一个问题——如何用更少,做更多。
价格战的背后,是效率基本功的碾压
这种效率优势,反映到价格上有多夸张?
V4 Flash版,每百万token最低仅0.2元、输出只要2元人民币。作为对比,同级别的海外模型少说也要几十块。Pro版报价24块,而性能对标的海外竞品普遍在100元开外。同等实际性能下,价差是5到20倍。而且随着国产通用算力芯片今年下半年大规模量产部署,这个成本还会继续往下探。
很多人觉得这是DeepSeek在发起行业价格战,但我认为这恰恰是它“效率基本功”碾压后的自然结果。当你的单token推理成本比对手低一个数量级的时候,无论定什么价,都是对竞品的降维打击。
更重要的是,价格降到这个份上,大量以前因为太贵而不敢尝试的AI应用,突然就变得可行了。小团队、个人开发者、非营利机构、教育场景,全都能参与进来。开源加上极致的成本控制,正在把AI从少数人的特权变成多数人的工具。
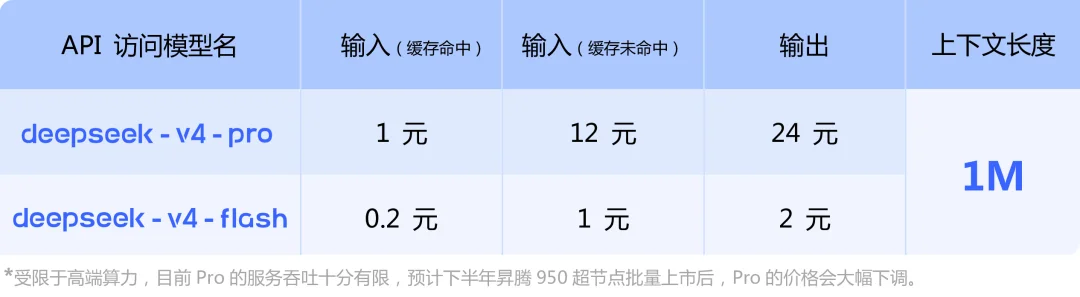 图来源:DeepSeek官网新闻《DeepSeek-V4 预览版:迈入百万上下文普惠时代》
图来源:DeepSeek官网新闻《DeepSeek-V4 预览版:迈入百万上下文普惠时代》
DeepSeek-V4 预览版:迈入百万上下文普惠时代
编程能力这件事,其实跟每个人都有关
常有人问:大模型卷编程,跟我写文案、做表格有什么关系?
我的答案是:在Agent时代,代码已经不是程序员的专属技能了,它是AI帮你干活的“手”。
你让AI做一份市场分析报告,它要自己搜索资料、验证信息真实性、把数据整理成图表、甚至发现矛盾后重新调整逻辑。这些你看不到的动作,每一步背后都是编程。看不见的代码输出,决定了你能看到的内容质量。
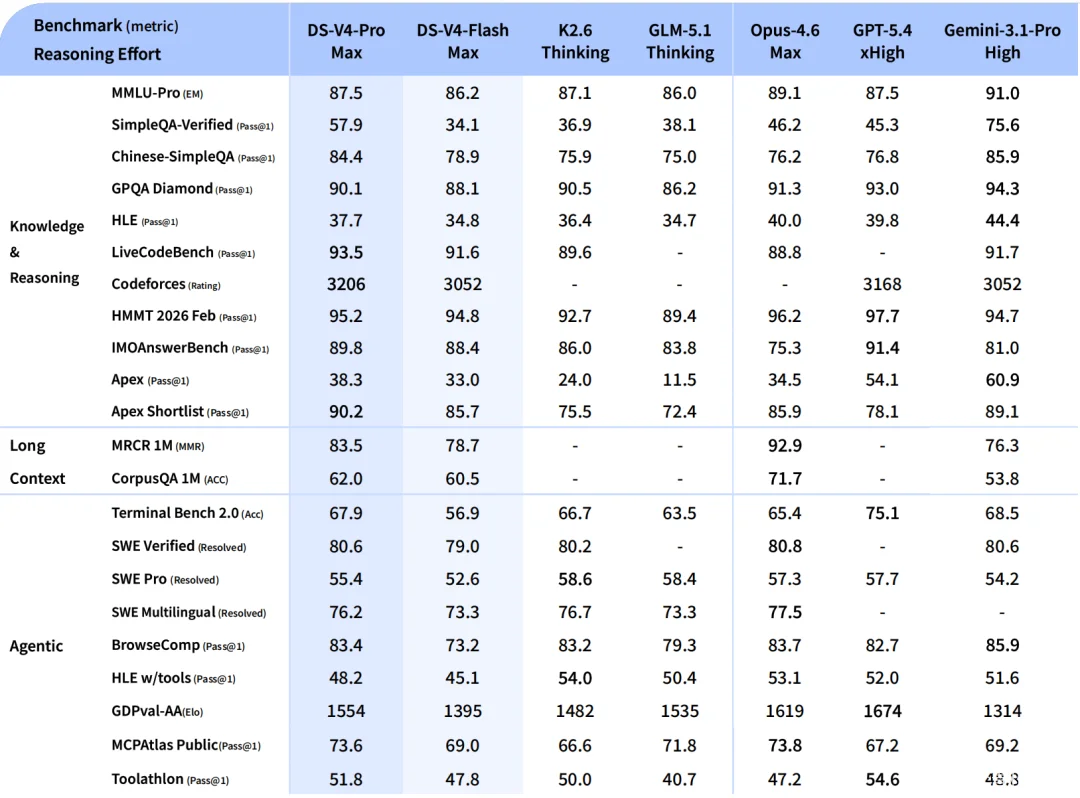
V4这次在编程上的硬指标很扎实:Codeforces编程竞赛基准评分3206,超过了Claude和GPT的最新稳定版本;真实软件工程基准SWE-bench Verified通过率达到80.6%,基本平齐行业最头部选手。技术报告还披露了一个更贴近真实场景的内部评测——从50多位内部工程师的日常研发任务中筛选出30道高难度编程题,V4 Pro的表现显著超越了Claude Sonnet 4.5,接近Claude Opus 4.5。在接受调查的85位深度使用V4编程的开发者中,超过91%的人认为它已经准备好成为主力编程模型。
但比起跑分,我更关注另一个维度的能力。在早期体验中我注意到一个细节:当任务执行到某个环节,调用的子Agent突然报错,V4没有中断流程,而是自主判断错误类型,换了一条路径继续推进,最终任务顺利完成。这种“卡住知道绕着走”的能力,在技术报告里可能只是一行“鲁棒性提升”,但在真实场景中,它意味着Agent从“演示可用”迈向了“生产可用”。而Agent能否真正从演示demo走向生产可用,决定性因素从来不是巅峰状态的智商上限,而是面对不确定性时的容错与恢复能力。
补齐最大短板,上下文从劝退变成劝留
过去DeepSeek最大的软肋是什么?上下文长度。
在对话AI时代,128K的窗口绰绰有余。但进入Agent时代,代码、指令、中间结果、格式信息全部塞进上下文,128K很快就捉襟见肘。这也是为什么过去很多人不用DeepSeek——不是因为它的语言能力不够,而是长度劝退。
V4这次直接把这个短板拉成了长板:100万token的上下文窗口,对齐了目前最顶级的水平。更夸张的是单次输出上限,384K,一轮就能输出完近30万字的长篇内容,几乎能装下整本《三体:地球往事》还有富余。在技术报告的长上下文评测中,V4 Pro在长文档机器阅读理解基准MRCR任务上甚至超过了Gemini 3.1 Pro,1万到100万token范围内的检索准确率几乎没有衰减。
这对重度用户和开发者来说,是实打实的体验解放。
 图来源:DeepSeek官网新闻《DeepSeek-V4 预览版:迈入百万上下文普惠时代》
图来源:DeepSeek官网新闻《DeepSeek-V4 预览版:迈入百万上下文普惠时代》
如果要说遗憾
如果说V4还有什么明显的缺口,那一定是多模态的缺席。
在2026年的今天,图像、语音、视频的理解与生成已经是行业标配,而V4依然是一个纯文本模型。这意味着在需要视觉理解或跨模态推理的场景里,它的应用边界会受到明显限制。
但仔细琢磨这个团队的逻辑,你会发现这不是疏忽,而是取舍。他们的资源池从一开始就没打算铺满所有赛道,而是集中砸在“语言基座”和“推理效率”这两个底层能力上。技术报告里明确写了,多模态能力正在研发中。但在此之前,开源MIT协议、允许商用、不加任何使用限制——这是把地基做到最坚固,至于房子怎么装修,交给生态去完成。它先回答了一个更根本的问题:在算力有限、硬件受限的前提下,一个模型能走多远。而它给出的答案,比大多数人预期的要远得多。
一篇技术报告里,藏着比跑分更值得读的东西
 图来源:DeepSeek官网新闻《DeepSeek-V4 预览版:迈入百万上下文普惠时代》
图来源:DeepSeek官网新闻《DeepSeek-V4 预览版:迈入百万上下文普惠时代》
翻完 DeepSeek V4的技术报告,最打动我的不是那些刷新 SOTA 的数字,而是几个很少有人会注意到的细节。
在评估结果那一章,有一句几乎可以当作范文的诚实表述。在对比 GPT-5.4 和 Gemini 3.1 Pro 的推理能力时,报告写道:V4 Pro Max“在标准推理基准上表现优于 GPT-5.2 和 Gemini 3.0 Pro,但略逊于 GPT-5.4 和 Gemini 3.1 Pro,表明开发进度大约落后最前沿闭源模型三到六个月”。没有 “各有千秋” 的公关话术,没有 “在特定条件下达到领先水平” 的模糊修辞。行就是行,差多少就是差多少。在一个人人都在把跑分包装成新闻稿的行业里,这种写法本身就是一种稀缺品。
另一个细节同样罕见。在评测章节的对比表格里,K2.6 和 GLM-5.1 的几项成绩是空白。旁边的注释只写了一句话:“因为它们的 API 太忙,没有返回我们的查询结果。” 就这么直白地放在正式技术报告里。换作大多数公司,会选择私下沟通补测,或者干脆换一组对比对象。但这份报告选择把真实过程原封不动地保留下来 —— 没拿到数据就是没拿到,不必遮掩。
报告的最后几页,是一份长达数页的致谢和作者名单。从核心研究人员到已经离开团队的成员(名字旁标着星号),从基础设施工程师到商务合规团队的每一个人,名字按字母顺序排列,没有任何头衔前缀。这种对每一位贡献者的尊重,和报告正文里的诚实是同一种底色。
我翻过不少大模型的技术报告,有的像精心策划的发布会 PPT,有的像律师审核过的免责声明。V4 这一份,更像一个工程师把调试日志整理出来给你看 —— 事无巨细,不太讲究表达的美感,但你知道他没有骗你。这种风格本身,就是这个团队最稳定的内核。
这份不炒作、不粉饰、不盲从的坦诚,正是这个团队刻在骨子里的行事准则,恰如他们在 V4 发布公告结尾写下的那句古训:「不诱于誉,不恐于诽,率道而行,端然正己」。不被外界的追捧与赞誉裹挟,也不因无端的非议与唱衰动摇,始终循着技术的本质前行,踏踏实实做好自己该做的事。他们说,感谢每一位用户的信任与支持,大家的肯定、建议和期许,是团队不竭探索、持续进步的动力,也让他们始终坚守初心,专注于不懈的创新。

写在最后
回到开头那个问题:DeepSeek掉队了吗?
我的答案是:它没有掉队,它只是走了一条和其他人都不一样的路。
当大多数AI公司都在拼命往模型里塞更多功能、追求更大规模的时候,DeepSeek在死磕一个词——效率。这条路在美国芯片禁令的阴影下,看起来是无奈之下的变通。但在全球算力荒的大背景下,这个被逼出来的选择,突然成了全行业最前沿的战略。
一个团队说开源,就真的MIT协议全部放出,不加任何使用限制。说长期主义,就真的扎在科研里半年不吭声,发论文、磨技术,外面传了好几轮“被超越了”,他们不回应,只是埋头干活。他们用行动印证了一句话:那些把你逼到墙角的封锁与限制,往往也是逼着你长出全新肌肉、走出全新路径的核心动力。
他们始终秉持着长期主义的原则理念,在 AI 这条充满不确定性的赛道上,于一次次尝试与思考中踏实前行,不贪一时的流量热度,不追短期的行业风口,只朝着实现 AGI 的目标,一步一个脚印稳步靠近。

 下个版本把它优化一下。
下个版本把它优化一下。